Abstract
Diffusion priors have recently demonstrated strong capability in enhancing the quality of sparse-view 3D reconstruction by augmenting training views at novel viewpoints, but they inevitably introduce hallucinated content-- artifacts inconsistent with the input views -- into the final 3D model. To address this challenge, we propose Hallucination-Aware Diffusion prior (HAD), which estimates pixel-wise hallucination score maps for augmented images by leveraging multi-view reasoning capabilities from a feedforward novel view synthesis (NVS) network pre-trained on large-scale 3D data. These hallucination scores enable selective masking of unreliable pixels during the progressive 3D reconstruction procedure, preventing the introduction of non-existent artifacts into the 3D model. To further enhance performance, we create multiple versions of augmented images at each novel view by conditioning the diffusion prior on different input views, which are then fused into a final image that leverages the broader context across all input views. We show that our method substantially reduces hallucination artifacts in diffusion-assisted 3D reconstruction, thereby achieving state-of-the-art performance across multiple benchmarks on novel view synthesis.
Method Overview
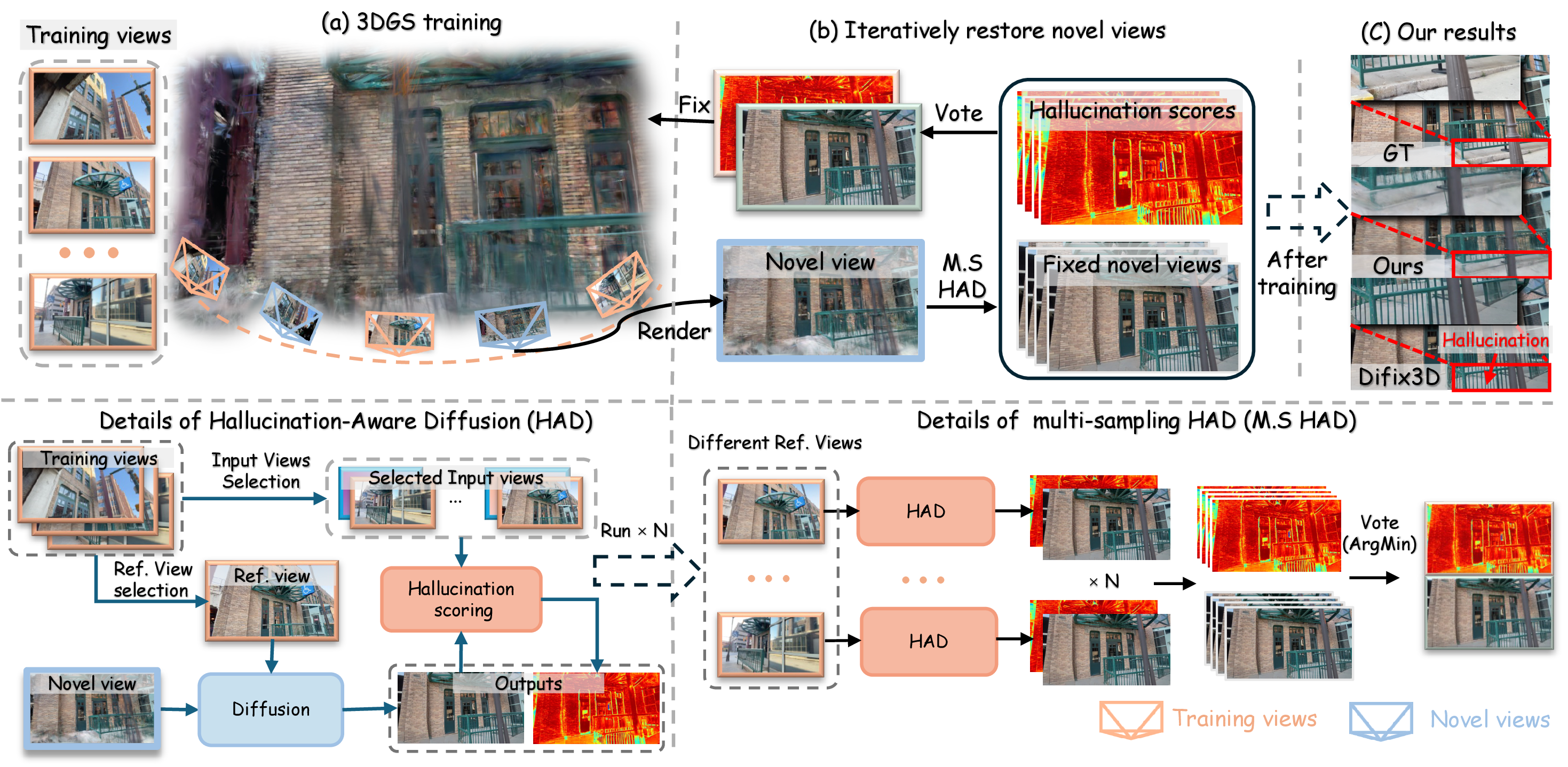
We train 3DGS with input images and HAD-augmented novel views. HAD combines a pretrained diffusion prior (which generates images from 3DGS-rendered views conditioned on reference input images) with our hallucination score network (which predicts pixel-wise reliability maps). Our multi-sampling strategy fuses multiple generated versions into refined augmented views. Hallucination scores guide 3DGS optimization by masking off unreliable content improving reconstruction quality in data-sparse scenarios.
Hallucination Detection
Our hallucination scoring network can recognize artifacts introduced by diverse generative priors, including image diffusion, video diffusion, and multi-view diffusion models.
Case 2



Case 1



Case 1



Case 2



Case 1



Case 2



Difix3D+ denotes a post-rendering diffusion pipeline, where 3DGS first renders a novel view and an image diffusion prior then refines the rendered image. The resulting hallucinations are not limited to extra objects or texture details that do not exist in the scene; they can also appear as geometric distortions, such as warped structures, inconsistent boundaries, or shape changes that break multi-view consistency.
Hallucination Removal Results
Our method effectively eliminates hallucination introduced by diffusion priors
DL3DV Dataset Results
Hallucination Analysis




Video Comparison: Navigate through scenes to see corresponding hallucination analysis above
MipNeRF360 Dataset Results
Hallucination Analysis


Video Comparison: Navigate through scenes to see corresponding hallucination analysis above
Direct Comparison with 3DGS-MCMC
DL3DV Dataset
Side-by-side comparison showing reconstruction quality improvements
MipNeRF360 Dataset
Evaluation on challenging 360° scenes